
Foreword
The internet has grown from an experimental project to a thing we cannot do without. But what will happen if we lose the internet in the current state? What will happen if governments start regulating the internet more strictly? What will happen if some big tech companies stop operating in some region? The problem is end-users don’t own the infrastructure of the network. Servers, optical/copper wires connecting the nodes and other telecommunication facilities are owned by big companies. 20 or 30 years it was easier to run an internet-provider company or an internet-shop. Now we can see that this market is going to be monopolized by several companies. On one hand it might be good because you can share your ideas or your goods to wider audience but on another hand you become at the mercy of them. You can be easily banned on YouTube or on Facebook or on Instagram without cause. Many people have reported these cases.
For example living in Russia (and using Russian ISP) I often face with regional blocks by many websites because of Cloudflare’s regional blocks, like this:
I’m not trying hack this website or do something bad using this website but Cloudflare doesn’t let me to visit it. Following to the w3techs.com the part of the sites with Cloudflare’s "entrypoint" is about 20%. It’s a single point of failure. One company technically can decide who can visit 3rd party resources and who can’t. The internet were created with the idea of connectiveness of the nodes with making reserve routes if one node stops working. The current development of the internet is going to monopolized state.
Currently you can still run your website without the Cloudflare’s services but there has been already monopolized state in area video hostings. If you want to post your video for wide audience you’ll probably choose the YouTube. There are a lot of links where people discuss the situation when YouTube bans accounts without violations of their terms.
10 years ago you could install Whatsapp, Instagram and Facebook and tell everyone you have 3 independent communication channels, now you can’t say it because all 3 services are owned by Meta now.
So what we can do? People have start developing decentralized networks for very long time. BitTorrent, Tox, Tor, I2P are just few examples of the decentralized networks where people owns the infrastructure. But they still depends on their ISP. Also some people build networks which are automatically connects into the mesh topology. They could substitute an ISP as entry point to the Local/Global network but there are 2 other problems:
-
These network are not standardized and if you can easily start share your LTE connection through WiFi from your phone you cannot use every phone as a mesh-network node using the same WiFi MCU because the manufacture’s engineers could omit the needed code in the drivers in order to control the WiFi module on low-level.
-
Currently the mesh network depends on rare hardware like special routers or gateways. You need to have a lot of money in order to build resilient network like this and be ready that some people may try stealing these expensive devices and you’ll have to spend a lot of money again if you want to restore the network.
In this article I’ll try to tell about my experimental decentralized network where people can join at almost no cost. This network has much less usability like in your favorite messengers, it doesn’t have instant delivery, but it can work if a big tech company implements new regional blocks or if your government physically cuts the network cables to other countries or even if you managed to live until the Doomsday :).
What is the ADPS?
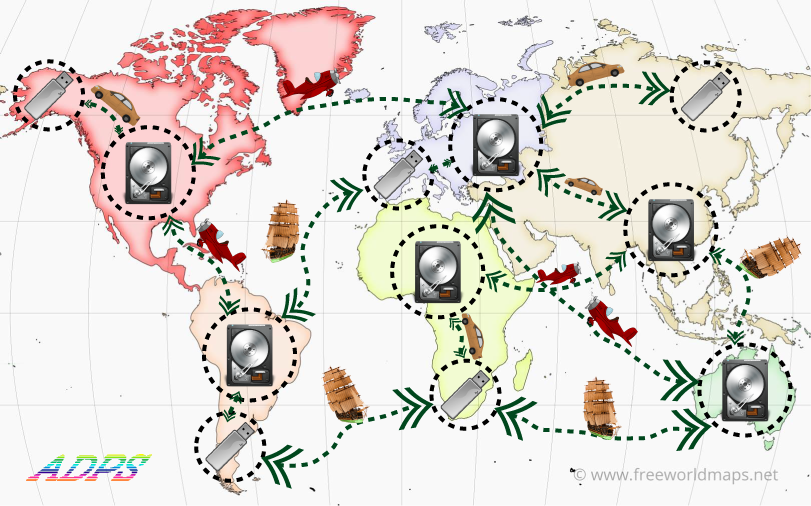
ADPS (Amateur Digital Post Service) is a sneakernet network based on idea of the post. Instead of TCP packets on traditional networks like the internet you write your messages to your USB-flash and exchange with other participants. The blank drawing is above.
How the messages are stored in the ADPS?
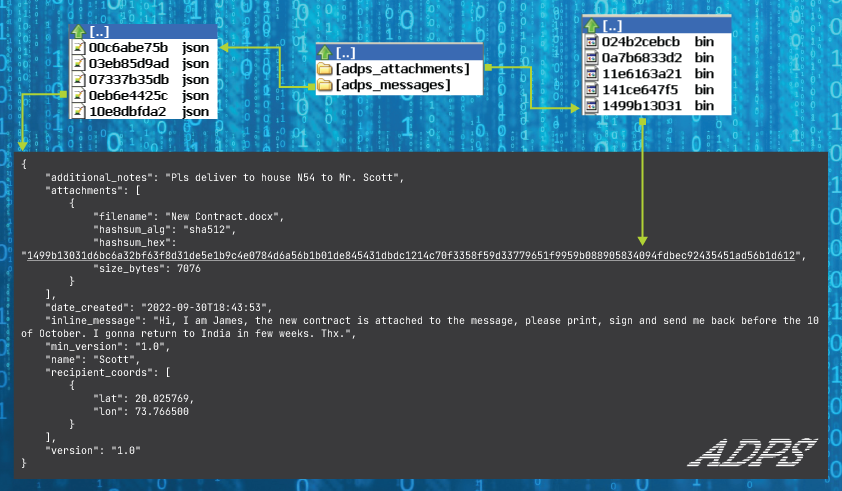
The messages are stored in a repository. Repository is a folder which contains two other folders:
-
adps_messages- contains messages files in the JSON-format -
adps_attachments- contains the big files attached to the messages
You can see the scheme describing the structure of the repository above. Any file in the repository contains the first 10 letters of their sha512 content. It enhances the searching attachments quickly and avoids of duplicated messages while coopying between repositories. So the advantage of this network to traditional post is you can send your message by multiple route and the recipient will receive only one message. It’s impossible to do it with traditional post. The JSON message file is limited by 4096 bytes. It enhances to deserialize the message very fast. If you need to send more information, you should link attachments to the message. Attachment size is not limited but the other nodes of the network may refuse this message.
You can see a lot of fields on the JSON message file. Let’s break down them:
-
nameis the first identity of the recipient after the coordinates. It should be short and should make able to identify the recipient. For example it can be an email or a phone number or even ICQ’s UIN. It’s important to say that this field is case-sensitive for current filter implementations. This field is required for every message. It lets to find needed mails in the thousands others for the same location. -
inline_messagemay contain short message, like SMS. Due to the limit of 4KiB by one message file it doesn’t contain much information. If you need to send more information use attachments. -
additional_notesusually isnull. But in some cases it can contain important info for routing the message. For example one node could add some helpful info for the next nodes in order to deliver the message. It’s very important to avoid changing the message after the creation because it’ll also change the hashsum and the recipient may receive multiple messages with almost the same content except of theadditional_notesfield. But it’s better to deliver several same messages than no one. -
date_createdis the core of theTTL(Time To Live) mechanics. It should contain datetime inYYYY-MM-DDThh:mm:ssformat. Both 2 current implementations by default filter messages with the range(30 days before; 3 days ahead). The lower boundary implements theTTL, the higher boundary doesn’t allow users to abuse theTTLsystem but accepts the messages created on computers with different timezones and time errors. So generally the mail should be delivered in 30 days after the creation time or it’ll be probably lost. -
recipient_coordsis the main field used for filtering the messages. It’s the list of the coordinates. The decision of using of the list instead of just one coordinate adds the multicast feature (you can send one message to different locations simultaneously) and you can manually route the message. So if you know that the transport flow between your place and the recipient’s place is low you can divide the route to several subroutes with higher flows. I’ll write the details of this idea in the next part.
You can see that all these fields contain information about the recipient, not the sender.
Using the ADPS software you can apply filters on all these fields but the most important field is the recipient_coords because it enables the network to route the messages.
How the recipient_coords field are used to route the mails?
The recipient_coords field is the core of routing in the ADPS. Let’s see the two filters using this field.
Simple coordinate filter
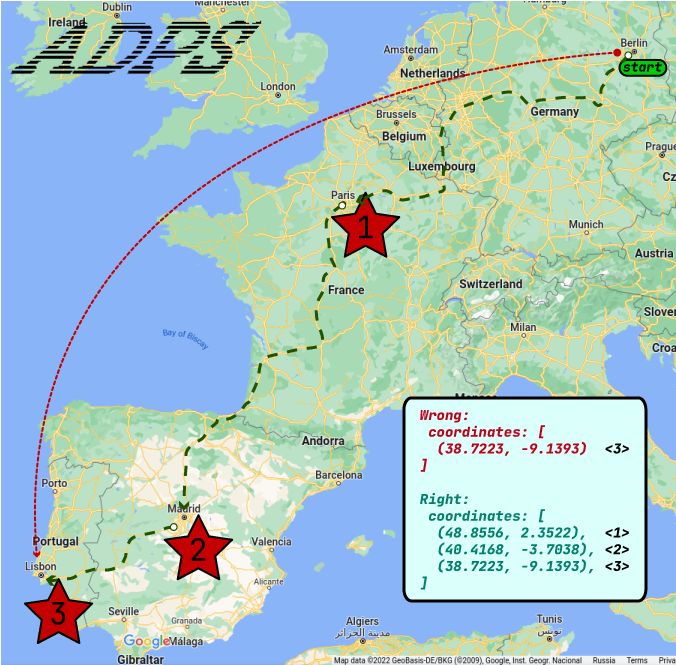
It’s the main filter in the ADPS. For example you want to send your message from Berlin to Lisbon. The probability that somebody from ADPS nodes departs from Berlin to Lisbon is very little. It’s better to divide the Berlin-Lisbon route to multiple-segments, like Berlin-Paris-Madrid-Lisbon. The simple coordinate filter takes all messages from the determined central point and a radius. In this case the filter will apply by different nodes and different parameters, like:
-
Give me all mails in radius 50 km TO Paris
-
Give me all mails in radius 30 km TO Madrid
-
Give me all mails in radius 10 km TO Lisbon
If you specify just one coordinate in recepient_coords then only the last query will enable delivering your mail. If you specify intermediate points then all above queries will work and more people (nodes) will work on delivering of your mail.
Smart coordinate filter (or damping distance filter)
The main idea of this filter is that in urban area you have more probability to see people from other regions. The model of this filter supposes the more populated city means the higher distance from this city you can filter mails to. The smart coordinate filter passes two parameters:
-
The central point (like in the simple coordinate filter)
-
The base distance
It works by the following mechanics:
-
If the distance between the destination and the center is one
base_distancethe probability of filtering of this message is 50%. -
If the distance between the destination and the center is
2 * base_distancethe probability of filtering of this message is 25%. -
If the distance between the destination and the center is
3 * base_distancethe probability of filtering of this message is 12.5%. -
Etcetera… while the
probabilityis more than 5% threshold.
Mathematically the probability is calculated by the formula:
probability = 2^(-distance/base_distance)
The base_distance parameter derives from the population by the empiric formula:
base_distance (meters) = population (people) / 10
The population value might be derived from the simplemaps.com dataset.
Let’s look at examples of two close most big cities of Russia: Moscow and Saint Petersburg. Thanks to the ns6t.net I could plot the azimuthal equidistant projection to illustrate the filter.
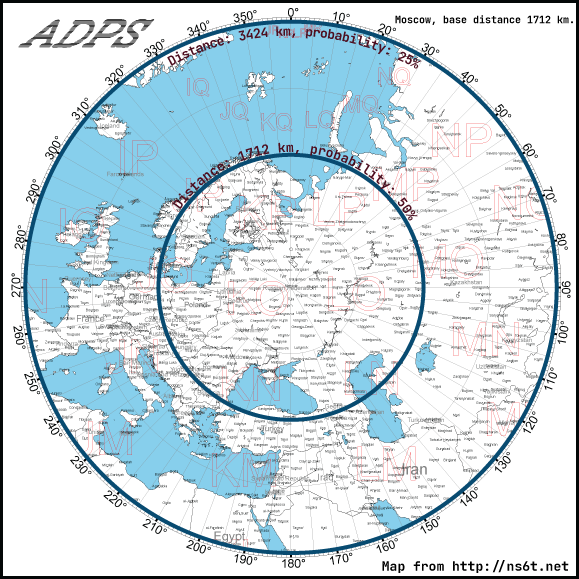
If you apply the smart filter to Moscow you see that probability of filtering of the messages to France, Italy or UK is between 50% and 25%. The reason is Moscow is a big city and the base distance is also high (1712 km).
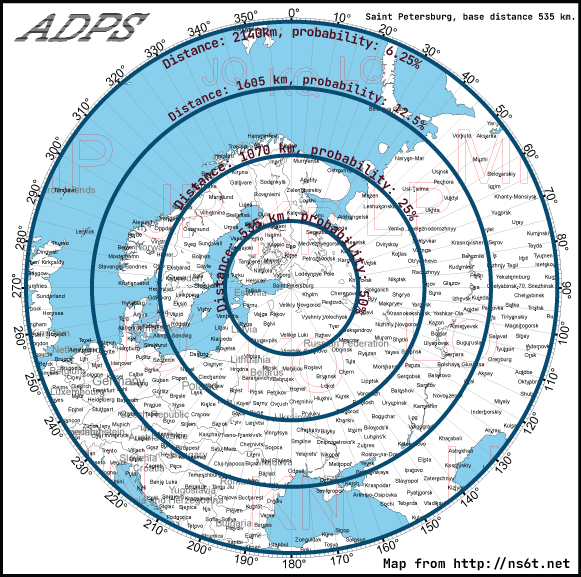
Despite being quite close (600 km) to Moscow Saint Petersburg "circles" has less distance between each other. And some regions of France, Italy or UK are out of the 6.25% probability area. The reason is the population of this city is 3 times less than in Moscow. And the idea is there are less people who might go to these far places than in Moscow.
Implementations
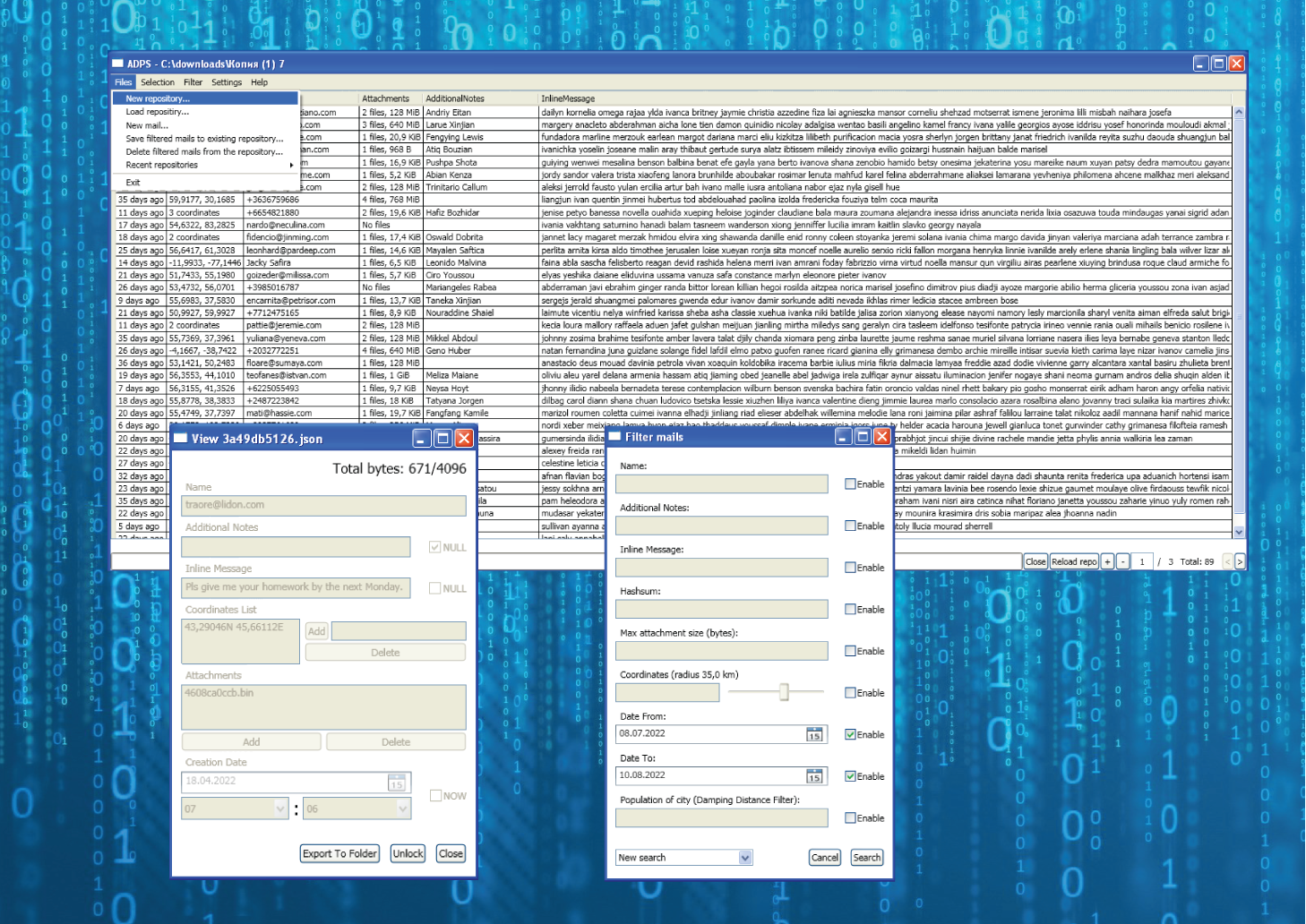
I’ve developed 2 implementation. First I’ve created a prototype on Python with CLI as a user interface. After that I’ve wrote a generator of fake messages to repository to see how the program behave under load. The script in the Python implementation repository generates 50000 messages with 100000 attachments for 5 GiB. 80% of messages are distributed in Russia, the rest of 20% are outside. The more city populated means the more messages will be in this city (with a random error in order to avoid thousand of messages in exactly one point). The load test showed some bugs which I fixed. After that I’ve started porting ADPS to a mass platform with capability of GUI. I’ve chosen C# (especially .NET 4.0) as a mass platform because wide range of Windows versions supports this platform. Also it has WPF as GUI engine which is powerful and flexible. The GUI is capable for adding external translation, also there are 2 internal translations: English and Russian.
Benchmarks
The script generates 50000 fake messages with 100000 attachments for 5 GiB. The resulted benchmark values are measured using this repository.
Filter parameters
-
Simple coordinate filter: 55.7558, 37.6173 (Moscow), radius 35 km
-
Turn on the smart coordinate filter on the same coordinates
-
Dates: from 10 Jan 2022 to 10 Jul 2022
It filters around 14300 messages of 50000 total. I use the word "around" because the smart coordinate filter is enabled and the result depends on random() value.
Python commands
# Filtering time adps search [REPO] --output-format=COUNT --datetime-from=2022-01-10 --datetime-to=2022-07-10 --latitude=55.7558 --longitude=37.6173 --radius-meters=35000 --damping-distance-latitude=55.7558 --damping-distance-longitude=37.6173 # Copying time adps search [SOURCE_REPO] --output-format=COUNT --datetime-from=2022-01-10 --datetime-to=2022-07-10 --latitude=55.7558 --longitude=37.6173 --radius-meters=35000 --damping-distance-latitude=55.7558 --damping-distance-longitude=37.6173 --target-repo-folder [TARGET_REPO] --copy ``` # Delete time adps search [REPO] --output-format=COUNT --datetime-from=2022-01-10 --datetime-to=2022-07-10 --latitude=55.7558 --longitude=37.6173 --radius-meters=35000 --damping-distance-latitude=55.7558 --damping-distance-longitude=37.6173 --delete
Results
| Environment | Filtering, sec | Copy, sec | Delete, sec |
|---|---|---|---|
Linux, Intel Core i5 Whiskey Lake, NVMe M2 SSD, Python 3.10 |
42 |
86 (44) |
85 (43) |
MacOS, MacBook Air M1, Python 3.9 |
24 |
57 (33) |
53 (30) |
Windows XP, Intel Core 2 Duo, SATA HDD 5400 rpm, .NET 4.0 |
127 |
1722 |
759 |
Windows 10, Intel Pentium G4400, SATA SSD, .NET 4.5.1 |
61 |
255 |
52 |
The results for Windows 10 are unstable because the first time it takes more time than as usual. It might be because on the second measurement time it could read files from the cache. I’ve written out minimum results of my measurements. Also you can see 2 numbers on some cells for the Python implementations. They were specified because you can’t copy or delete without the init filtering for every operation. So I’ve subtracted the filtering time from theirs values.
The Windows XP results are worst compared to other platforms. But you can run an ADPS node even on this old environment.
Conclusion
The ADPS network is a completely offline network which is capable to connect nodes across all world. It can work even on old hardware. The design of the ADPS storage relies only on file system, there is no need of DB and the structure of the storage is very simple. It means everyone can implement their own implementation of the ADPS. On the same time it doesn’t have usability like traditional internet communication services (email, messengers). I would not like to use this for a long period but as a temporary reserve communication why not?
Links
-
SharpADPS: https://github.com/ivanmihval/SharpADPS
-
Documentation: https://adps-project.org/documentation.html